
Shikhar Saini, Santiago Guerra, Ali Mai, Andrés Vázquez
Mental health in the workplace is an issue that more and more companies are concerned about. According to the World Health Organization (WHO), more than 300 million people worldwide suffer from depression. This and other types of illnesses and disorders have a direct impact on productivity levels in the company.
The work environment and how work is managed directly influence the mental health of the workforce. In fact, mental disorders are the second most common health problem in the workplace. Therefore, organizations must take an active role and promote effective workplace actions to contribute to their employees’ well-being.
Why is mental health important at work?
Healthy mental health at work is closely linked to positive economic results, conflict management, customer satisfaction, and the achievement of organizational efficiency. A happy employee will be much more productive, will be more committed to the company, will make fewer mistakes and will offer better customer service if they understand the purpose of their work and receive support for their mental health in the work environment. In general, it increases the competitiveness of the organization.
Companies can implement many effective measures to promote mental health in the workplace, thereby increasing productivity and at the same time improving the quality of life of their employees, who spend most of their day-to-day lives with their managers and colleagues.
How to identify workplace conditions that give rise to signs of mental illness in employees?
In response to this concern, Open Sourcing Mental Illness (OSMI) has conducted a survey of tech industry workers to better understand the prevalence and impact of mental health issues in this field and collected data. In this project, we will use this survey dataset to apply machine learning algorithms to uncover the workplace conditions that produce these mental disorders in employees.
Our goal is to develop a better understanding of the factors that contribute to mental health issues in the industry and to identify potential interventions and solutions that can help improve the well-being of tech workers. By shining a light on this important issue, we hope to raise awareness and encourage action to support the mental health of tech workers. In order to achieve this goal, we are going to develop some machine-learning models to get insights into the data we have.
Dataset description
The dataset consists of a survey from 2014 to 2021, and it aimed to measure attitudes towards mental health in the tech workplace. We merged the datasets and finished with 27 features in one single dataset, most of them being categorical variables. Since it is a survey, all answers came in the form of binary (yes/no), or categorical (easy, moderate, difficult). We divided the dataset according to whether features could be controlled by the company or not. 14 attributes cannot be controlled by the companies, while 13 attributes can be controlled by the company.
Target Variable for Classification

We chose Work_interference as our target variable because it not only indicates which individuals have a mental illness but also reveals the extent to which their work is impacted by it.
What kind of companies look after their employees?
In order to segment companies according to their mental health attitude, we need to identify common patterns and trends in the data by grouping data points that are similar to each other (clustering). This will allow us to make company profiles and characterize them. As we want to identify mental health risk factors in a workplace, we only consider the variables that are in control of the company, i.e., the number of employees, mental care options, wellness programs, etc.
How many types of companies?
We determined the optimal number of groups (clusters), which is not just a random number, that’s why we use quality indexes that will evaluate the quality of a clustering. The idea is to launch several runs of a clustering algorithm with various initial numbers of clusters. The optimal number of clusters is the one for which the quality index is maximized. In this case, we used the silhouette index using a number of clusters ranging from 2 to 5. Additionally, we used the elbow method, which calculates the within-cluster sum of squared errors (WCSS) for different cluster sizes to determine the optimal number of clusters. With both techniques, we found out that 3 clusters is the optimal amount of groups for this dataset, meaning that there are 3 types of companies that show a different attitude towards mental health.


Company Profiles
By projecting the data onto a lower-dimensional space, it was easier to see the clusters and see how they are separated from each other. As you can see in the figure below, there are 3 visible groups that helped us create profiles.

To compare the characteristics of the clusters, we created radar graphs of every feature to represent the data, as they provide a clear visual representation. We discovered that the clusters have the following characteristics:
Profile 1
- A medium-sized company, with between 11-100 employees
- The company doesn’t provide resources to learn more about mental health issues and how to seek help
- Employees don’t know the mental health care options his/her company provides
Profile 2
- A big company, with more than 1000 employees
- The company provides mental health support benefits to employees
- The company provides resources to learn more about mental health issues and how to seek help
- Employees know the mental health care options his/her company provides
- It is very easy to take medical leave for a mental health condition
Profile 3
- A small-sized company, with between 1-10 employees
- Mental health support benefits are not known by their employees
- Not sure that the company provides resources to learn more about mental health issues and how to seek help
- Employees are not sure about the mental health care options his/her company provides
- It is moderately easy to take medical leave for a mental health condition


A Closer Look at the Data
From the variable work_interfere we know if an employee has had a mental issue that interferes with their job performance. We create 8 different classification models for the employees in order to know whether they’re gonna have a mental issue or not.
From the 8 models that we trained, the best three were: Grid Search SVM, SVM, and Logistic Regression. Each one of these three gets a score really near 0.8 which is nice. As we can see in the confusion matrices it tends to predict correctly whether a person will have a mental issue or not.

So as we can see we can predict, from the features that we have, if a person will have a menthol issue or not.
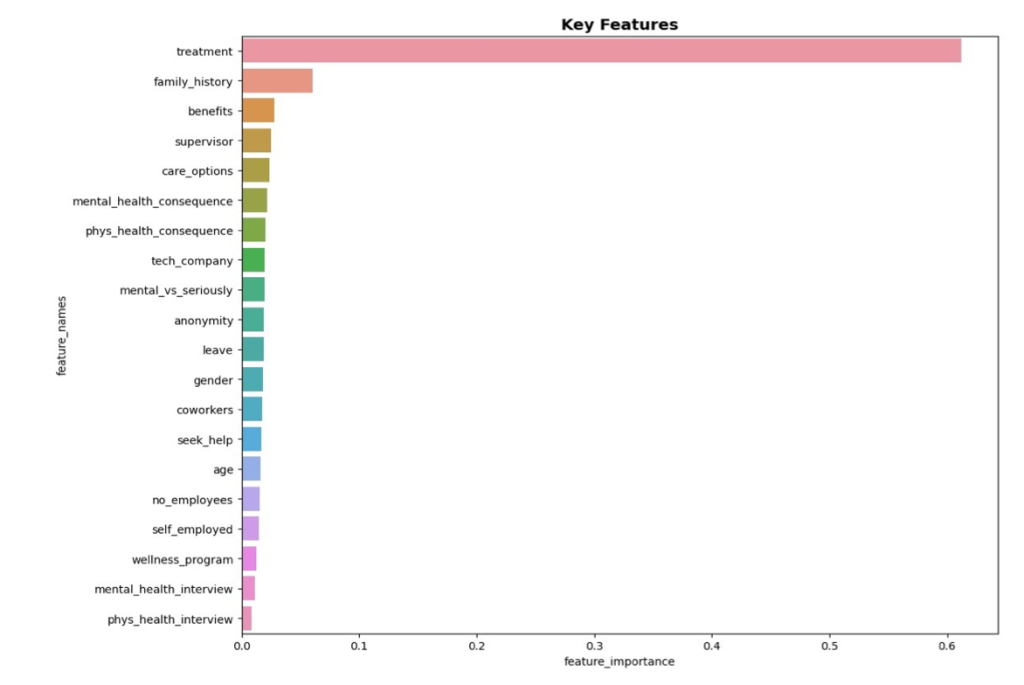
From the analysis we made about the importance of the features that we have, we can say that the main variables that can lead a worker into a mental breakdown and are in control of the company are, the benefits the employees have related to mental health and the trust they have to talk about mental health with their supervisors. These variables the company can change, like giving more benefits or training the supervisors in order to make their employees trust them with any issue they have.
Conclusion
The project aimed to explore key features in mental health in the employees of the tech industry through machine learning. The optimal number of clusters in the dataset was found to be 3 and predictive modeling techniques were applied to make predictions about mental health issues. The algorithms achieved an accuracy of between 0.71% – 0.80%, and an F1 score of 0.80%. The study found that “treatment”, “family_history”, “Benefits”, and “Supervisor” were significant factors impacting mental health and working capability.
Future Scope
- Mental illnesses will become a growing concern in the tech industry, with the increasing workload and competition putting pressure on workers.
- There is a requirement for a proper database with vast, consistent data to better understand and address the issue.
- Additionally, more efficient algorithms are needed to detect and analyze human emotions, so that we don’t have to rely on survey systems for collecting data and the data will have more authenticity.
- Increasing awareness of the problem is also crucial in making mental health a mainstream concern in the tech industry. For now, there are very few NGOs or companies that consider mental health issues serious business, also this issue is mostly only addressed in developed nations.
- By addressing these issues, the industry can improve the overall mental well-being of its workers, and ultimately it can help to increase the productivity of the company itself.
References: